Programação se torna o novo painel de controle da IA com lançamentos do GPT-5.3-Codex e Claude Opus 4.6
O cenário da inteligência artificial se transforma com novos modelos de programação.
Desde a sua estreia em novembro de 2022, o ChatGPT da OpenAI se destacou como um líder no campo da inteligência artificial. Contudo, as dinâmicas do setor tecnológico são voláteis e, em 2026, a posição da OpenAI poderá ser bastante alterada.
O Google, com o lançamento do Nano Banana Pro, conquistou a atenção do público, enquanto o Gemini tem se estabelecido como um chatbot de inteligência artificial em ascensão. Em contrapartida, a participação de mercado do ChatGPT tem enfrentado uma queda significativa em algumas regiões. A Anthropic, por sua vez, firmou-se como uma autoridade em engenharia de software, tornando-se uma ferramenta bastante utilizada entre programadores.
Recentemente, observou-se um fenômeno interessante na corrida pela liderança em IA: o lançamento quase simultâneo de dois novos modelos focados em programação, o GPT-5.3-Codex e o Claude Opus 4.6. Essa coincidência sugere uma intensa competição entre os principais atores do setor, beneficiando diretamente os usuários.
Com esses novos modelos disponíveis, surge a questão sobre suas contribuições reais. Promessas e benchmarks estão começando a emergir, oferecendo uma base para análise mais aprofundada do que OpenAI e Anthropic têm a oferecer para aqueles que utilizam IA como ferramenta de desenvolvimento.
GPT-5.3-Codex e Opus 4.6: promessas para desenvolvedores
O GPT-5.3-Codex é um modelo projetado para agentes de programação, visando ampliar as capacidades que um desenvolvedor pode delegar à inteligência artificial. A OpenAI destaca que este modelo apresenta melhorias significativas em desempenho, raciocínio e conhecimento profissional, além de ser 25% mais rápido que suas versões anteriores.
Esse modelo é otimizado para tarefas prolongadas que exigem pesquisa, uso de ferramentas e execução de processos complexos, permitindo intervenções em tempo real sem perder a continuidade do trabalho.
Um aspecto notável do desenvolvimento do GPT-5.3-Codex é a utilização de versões anteriores do Codex para otimizar o treinamento e a análise de resultados, acelerando os ciclos de pesquisa e engenharia.
Além disso, o GPT-5.3-Codex mostra avanços em tarefas práticas, como a criação autônoma de aplicativos web e jogos. Exemplos de jogos, como um de corrida e outro de mergulho, estão disponíveis para experimentação.
Por outro lado, a Anthropic apresenta o Claude Opus 4.6 como uma atualização focada em planejamento, autonomia e confiabilidade em grandes bases de código. Este modelo é capaz de realizar tarefas autônomas por períodos prolongados e revisar seu próprio trabalho com maior precisão.
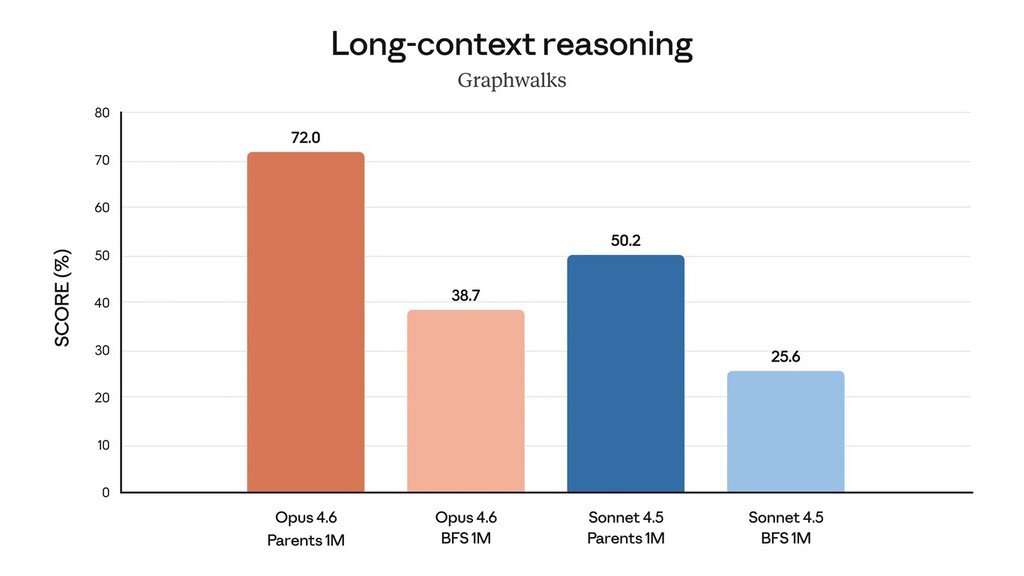
Essas capacidades são aplicáveis em diversas tarefas, como análise financeira e criação de apresentações. O modelo também oferece uma janela de contexto de até um milhão de tokens em versão beta, visando minimizar a perda de informações em processos longos.
Além do núcleo do modelo, a Anthropic introduziu várias melhorias para prolongar a utilidade do Opus 4.6 em fluxos de trabalho reais, incluindo um mecanismo de “pensamento adaptativo” que ajusta automaticamente a profundidade de raciocínio conforme o contexto.
O Opus 4.6 também permite configurações de esforço ajustáveis e técnicas de compressão de contexto, facilitando longas interações sem esgotar os limites de uso. A integração com ferramentas como Excel e PowerPoint foi aprimorada, permitindo uma coordenação mais eficiente entre equipes de agentes.
Algumas empresas já tiveram acesso antecipado ao novo modelo da Anthropic, que apresenta depoimentos positivos sobre suas capacidades em gerenciar tarefas complexas de forma autônoma.
Embora o GPT-5.3-Codex ainda não esteja disponível em APIs, o modelo da Anthropic já está no mercado, com um custo base acessível em relação ao uso de tokens.
Análise comparativa: quem se destaca?
A comparação entre GPT-5.3-Codex e Claude Opus 4.6 enfrenta desafios, principalmente pela dificuldade em alinhar dados e metodologias de avaliação. Cada empresa tende a destacar métricas que favorecem seu progresso, dificultando uma análise direta.
A fragmentação dos resultados reflete o estado atual da tecnologia, exigindo uma interpretação cuidadosa que separe demonstrações técnicas do verdadeiro potencial. Apenas através dessa análise é possível identificar os pontos em que ambos os modelos podem ser avaliados em condições