Google desenvolve novo método de compressão que reduz significativamente o uso de memória em processos de inteligência artificial
Nova técnica do Google promete revolucionar a memória em modelos de IA.
Recentemente, um estudo do Google Research apresentou uma inovação significativa na área de inteligência artificial: a técnica TurboQuant. Este algoritmo de compressão tem o potencial de reduzir a memória de trabalho dos modelos de IA em até seis vezes, mantendo a qualidade e o desempenho.
Para compreender a eficácia do TurboQuant, é essencial saber que a memória que ele comprime é utilizada para armazenar o contexto de conversas longas. Cada token processado é guardado no KV cache, que aumenta conforme a interação se estende. Esse crescimento contínuo da memória é um dos principais desafios durante a inferência de IA, exigindo grandes quantidades de memória RAM ou HBM nos centros de dados.
O TurboQuant aplica um método de quantização vetorial no KV cache, permitindo a compressão sem comprometer a precisão do modelo. Essa abordagem pode transformar a forma como os dados são processados, oferecendo soluções mais eficientes para as empresas que utilizam inteligência artificial.
Seis vezes menos memória
De acordo com o estudo, a aplicação do TurboQuant pode resultar em uma redução de seis vezes na KV cache, sem que haja uma diferença notável no desempenho durante conversas extensas. Os pesquisadores planejam apresentar suas descobertas em um evento no próximo mês, detalhando os métodos que possibilitam essa compressão. Se os resultados se confirmarem, as implicações são vastas: menos memória necessária para inferência pode levar a uma significativa diminuição nos requisitos de hardware e memória nos centros de dados.
A descoberta gerou comparações com momentos marcantes na indústria, como o impacto da startup DeepSeek, que introduziu um modelo de IA com custos de desenvolvimento muito inferiores aos concorrentes. Avanços técnicos que promovem eficiência são cruciais no setor de IA, onde os recursos exigidos são imensos. Testes preliminares com o TurboQuant já indicam que o método é eficaz.
As consequências da técnica começam a ser percebidas nas avaliações das ações das fabricantes de memória DRAM e HBM. Empresas como Micron, Samsung e SK Hynix enfrentaram quedas significativas nas bolsas, refletindo a expectativa de um mercado que pode ser impactado pela nova tecnologia. As ações dessas empresas caíram drasticamente, evidenciando a preocupação com a possível diminuição da demanda por memória.
Mas há um porém
É importante notar que a técnica TurboQuant se aplica apenas à fase de inferência, enquanto a fase de treinamento dos modelos de IA continuará a exigir grandes quantidades de memória. Assim, será necessário aguardar a adoção prática dessa tecnologia pelas empresas de IA para avaliar seu impacto real. Embora a compressão permita uma maior flexibilidade para as grandes empresas, não há garantias de que isso resultará em uma redução nos preços por token.
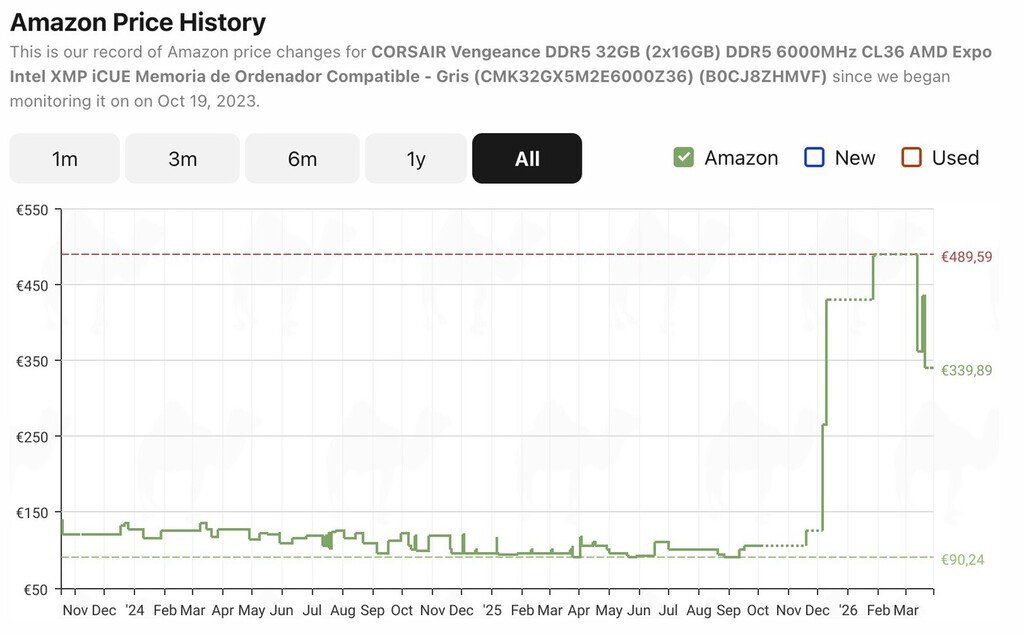
Além disso, o impacto do TurboQuant também se reflete nas oscilações de preços dos módulos de memória. Por exemplo, os módulos Corsair Vengeance DDR5 32 GB 6000 MHz tiveram uma redução significativa em seu preço nas últimas semanas. No entanto, nem todos os componentes de memória estão apresentando quedas semelhantes, e as variações nos preços podem estar mais relacionadas a ciclos de oferta e demanda do que à nova tecnologia em si.